お知らせ
2024/06/16:西洋古典に特化したAI対話システム「ヒューマニテクスト」の開発
田中一孝(桜美林大学)
2024年6月2日、日本西洋古典学会第74回大会のお昼休みの時間をいただき、西洋古典に特化した生成AIシステム「ヒューマニテクスト」(英名:Humanitext Antiqua)の開発報告と、デモ展示をしました。今回、会場にいらっしゃらなかった会員の皆様にもHP上でこのシステムをご紹介する機会をいただきました。そこで、ヒューマニテクストとはどのようなものか、システムの開発経緯を含めてご紹介します。また、このシステムがどのように西洋古典の研究や教育に役立つのか、課題や展望についても論じたいと思います。
I. 開発の経緯
ヒューマニテクストは名古屋大学の岩田直也さん、国立情報学研究所の小川潤さん、そして私の3人で開発したシステムです。きっかけは前年の大会(第73回)のフォーラム「西洋古典学とデジタル・ヒューマニティーズ」に遡り、そこでは岩田さんがChatGPTの研究利用について、小川さんは西洋古典における人文情報学の全体的潮流について報告しました。
2022年の11月にOpenAIからChatGPTがリリースされたとき、まだまだ研究には使えないと多くの人は思ったはずです。しかし、2023年3月に新しい基盤モデルGPT-4が実装されると雰囲気は一変しました。GPT-4は、非常に自然で論理的な文章を生成し、様々な客観テストでも好成績を収めることができました。私は西洋古典の専門家として、ギリシア語やラテン語の翻訳が比較的高精度で可能なことに着目していましたが、より興味深く思えたのは、ユーザーが用意した特定のデータベースと連携できることです。ネット上では会社経営者が自著をもとに社訓を生成させたり、「設定」に基づいてゲームキャラクターに画面上で話させたり、様々な事例が報告されていました(現在では、非常に多くの企業・組織が自前のデータベースと生成AIを連携させて業務を遂行しており、大学もまた例外ではありません)。同様に西洋古典のデータベースと連携させれば、テクストに基づいた「解釈」を生成できることは容易に想像できます。
会員の皆様はご存知の通り、Perseus Digital Libraryでは西洋古典のテクストの多くがデータ化され、無料で公開されています。この背景には西洋古典は人類の知的源泉であり、誰もが無料で簡単にアクセスできるべきだという思想があります。こうした先人たちの蓄積を生成AIの技術と組み合わせることができれば、西洋古典学は飛躍的に発展するのではないか。日本の西洋古典研究者は、Perseusだけでなく、Thesaurus Linguae Graeca、Digital Loeb Classical Libraryなど、海外の研究者が開発してきたデジタルプラットフォームの一方的な受益者だったが、日本発の新しいシステムを作って国際的な貢献ができるかもしれない。私と岩田さんは、フォーラム前日に居酒屋でこのようなことを話していたのですが、なにしろ情報学の素人であり、こうしたアイデアの実現可能性について判断ができませんでした。しかし幸運だったのは、フォーラムで知り合った小川さんが、人文情報学の専門家で、ローマ史の研究者でもあること、そしてPerseusプロジェクトを牽引してきたGregory R. Craneの思想に深く共感していたことです。私たちは大会後、取りあえず話そうと入った上野の居酒屋で意気投合し、ヒューマニテクストの基本思想はほとんどそこで決まりました。
その後はそれぞれが生成AIに関する研究会や講演会に顔を出し、情報収集をすすめました。また、こうした技術に完全に素人な私は、「初めてのプログラミング」的な本を何冊か購入するところから始まり、Youtubeの初心者向け動画を視聴し、わからないところはChatGPTに尋ね、それでもわからなければ海外のフォーラムで調べるのが習慣となりました。
II. ヒューマニテクストで何ができるか
ヒューマニテクストは著作家の原典テクストをもとに、ユーザーが記した文章・質問に対して、応答をするシステムです(図1)。このシステムが何をできるのか、具体例を通じて簡単にご紹介したいと思います(現在、完全公開に向けてシステムを大幅に刷新中であり、ここでご紹介する画像はデモ版と考えてください)。
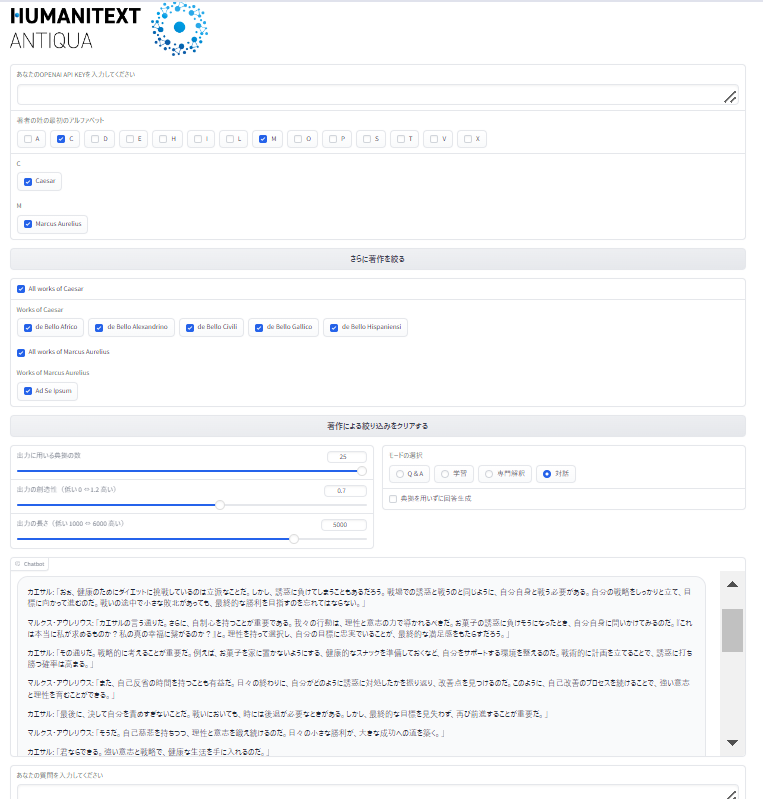
図1:ヒューマニテクストのインターフェース
ヒューマニテクストは、特定の著作家や著作を参照すべきデータベースとして選択可能です。たとえば、イソクラテスを選択し「イソクラテスは正義の概念をどのように論じていますか?」と質問すると次の画像のように回答が生成されます(図2)。

図2:「イソクラテスは正義の概念をどのように論じていますか?」への回答
ヒューマニテクストは、専門研究に活用できるよう、ほぼ全てギリシア語、ラテン語の原典でデータベースを整備しています。ユーザーの関心に基づいた質問に対して、システムは原典を文脈探索し、それに即した解釈を生成します。ヒューマニテクストの重要な特徴として、生成した解釈のもととなったテクストソースを示す点が挙げられます(図3)。
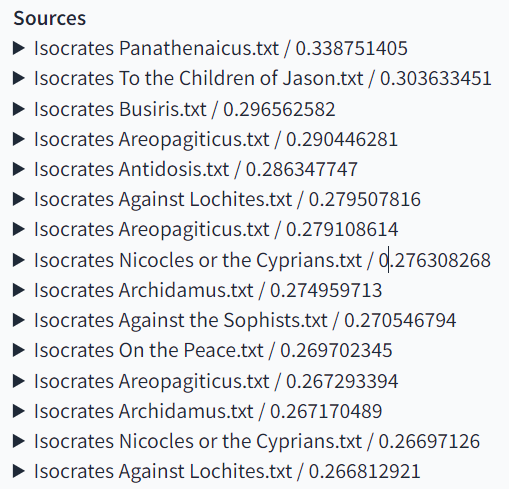
図3:「イソクラテスは正義の概念をどのように論じていますか?」への回答に用いられたテクストソース
この図は、テクストソースの一覧ですが、クリックすれば実際に原典を参照することができます。生成AIを研究に活用する際にしばしば問題になるのが、偽情報の生成、いわゆる幻覚(ハルシネーション)です。我々はこの問題を低減するために、(1)確かなデータベースに基づいて情報を生成する、(2)ユーザーがテクストソースを直接確認できるようにする、という対策を講じました。これによってユーザーは、生成結果の真偽を確かめることができ、また生成結果にあまり反映されていない関連文脈も調べることができます。これは言わば、AIの利便性と限界を同時に確認できるシステムと言えるでしょう。
ヒューマニテクストでは生成された結果について、特定の著作データにテクストソースを絞りながら、さらなる詳細な説明を求めることができます。あるいは、他の著作家のテクストに基づいて質問をすることもできます。たとえば、プラトンを選択して「このイソクラテスの正義についての考え方と、プラトンの正義論を比較してください」などと尋ねることができます。どのような著作家・著作をデータベースとして用い、どのように質問を重ねていくのか、その組み合わせは無限であり、今まで誰もできなかったような比較研究、領域横断研究が可能になると考えられます。
ヒューマニテクストは現状、4つのモードを実装しています。
- Q&Aモード:質問に対して1問1答形式で簡素に情報を生成する。
- 学習モード:ギリシア語・ラテン語は全て翻訳して引用し、質問内容に関する背景知識も踏まえて回答を生成する。
- 専門解釈モード:ギリシア語・ラテン語を直接引用し、ときには文法や用法に踏み込んだ複雑な解釈を生成する。(上の画像はこのモードを使用)
- 対話モード:システムが指定した著者やその著作の登場人物の人格や文体を模倣し、ユーザーは疑似的に古代の偉人との対話を楽しめる。
対話モードは一般の方でも気軽に古典を楽しめるよう設計したものです。たとえばカエサルとマルクス・アウレリウスに対して「私は健康のためにダイエット中ですが、どうしても誘惑に負け、お菓子などを間食してしまいます。私はどうすべきか対話形式で話し合ってくれませんか?」と投げかけると、次のような結果が返ってきます(図4)。

図4:対話モードの例
どうでしょうか。ユーモアを感じる文章ですが、カエサルとマルクスの特定のテクストに基づいており、根拠のない回答ではありません。他方でこれは、カエサルやマルクスの一部を切り取って疑似的に再現しているものであり、全思想を反映しているわけでもありません。このモードは西洋古典を創作や楽しみのために大いに活用してもらいたいと設計しましたが、同時に多くの方々がさらに古代の人々の思想を深く知りたい、実際に古典を読みたいと思うきっかけになればと考えています。
※質問と応答の事例については、公式xアカウントで多く紹介しておりますので、詳しくはそちらをご覧ください。
III. 今後の展望と課題
ヒューマニテクストは夏までの一般公開を目標に現在システム改修を進めています。このシステムはChatGPT同様、質問する言語と同じ言語で応答できるので、世界中の人たちに使ってもらいたいと思っています。こうした開発を進める過程で見えてきたものを、課題と展望を含めていくつか述べたいと思っています。
研究と教育の質の変化
私たちはヒューマニテクストの生成する解釈の質にはまだ満足していませんが、現状でも研究に十分活用できるレベルには達していると考えています。とりわけ意味や文脈に即した探索能力は強力で、システムに習熟すれば、ある特定の概念の用例やトピックを膨大な文献を対象に一瞬で調査することが可能です。これは私も含め、多くの研究者が専門性に基づいて時間と労力を割いていた用例探索の作業が、ある程度は非専門化、「コモディティ化」することを意味しています。しかしこのことは、そうした作業とは別の時間、たとえば既存の分野にとらわれずに創造的に問いを立て精緻な解釈を施す時間が増すことも意味します。私たちはヒューマニテクストを通じて、より高度で多くの研究成果が生まれることを期待しています。
教育も大きく変わるかもしれません。ヒューマニテクストを用いれば、学生は教員がこれまでに読んだことのない文献を探索し、新しく興味深い研究のアイデアを量産し、形式的には原典に基づいてレポートや論文を書けるようになります。一方で、原典を正確に解釈できているのか、その解釈はより大きな文脈を踏まえているのかは依然として問題となるでしょう。私たちが受講してきた講読や演習授業の価値は、今後ますます高まるように感じています。
現在私たちは、ヒューマニテクストを用いた教育プログラムの構想に着手しています。ぜひ古典学会会員のみなさまにも、こうした新しいテクノロジーをどのように教育に活用するのか、そしてこのツールの利用が一般化した状況でどのような研究が評価されるのか、ガイドラインの整備も含めて議論をしていただきたいと思います。
データベースの拡張と研究者の育成
現在、ヒューマニテクストは22の著作家の著作データベースを整備していますが、今後は現在に伝わる西洋古典全てを所収していきたいと考えています。また著作権的に問題の無い二次文献や、著作権者と合意できた二次文献もまたデータベースに含めることを考えています。さらに将来的には、他の時代、地域、分野の専門家の方々と協調しながら、人文学やその枠にとどまらない知的プラットフォームを構築できないかと模索しながら研究を進めています。
現在、こうしたAIを活用した人文学やシステム開発について、専門的に携わっている研究者はほぼ存在しません。ヒューマニテクストはなんとかここまでこぎつけましたが、たった3人では限界があり、今後はこうした研究開発に携わる研究者の育成が急務です。今年の3月、名古屋大学デジタル人文社会科学研究推進センター主催のシンポジウム「AIで切り拓く人文学の未来」において、ヒューマニテクストのプロトタイプを公表した際、とても印象深い質問をいただきました。すなわち、こうした人文情報学の重要性は十分に認められるが、こうしたシステム開発に携わることで、哲学や文学、歴史の専門研究の時間が奪われるのではないか、といったものでした。これは全くその通りで、私も昨年からプログラミングの勉強にかなりの時間を割いていますし(岩田さんは既に相当の腕前です)、小川さんは西洋史から人文情報学に専門を変えたという経緯があります。個人的には、データベースを自分で整備し、システムの挙動を制御するスキルは、自身の哲学研究にも寄与すると考えていますが、既に職のある私たちはともかく、これから学生が類似したプロジェクトに携わったときに、その研究活動が適切に評価される仕組みが必要だと考えています――おそらく学生が就職活動をする際には高く評価されるでしょうが。
サステナビリティ
ヒューマニテクストは現在、基盤モデルとしてOpenAIのGPT-4oを採用しています。このモデルを使用するには、通信やデータ処理のためのコストがかかります。研究開発用にかかるコストはわずかですが、多くの方に使用していただけた場合、私たちにはその料金を全て負担することができません。そこで一般公開の際には、ユーザー自身がOpenAIと契約し、使用量に応じて料金を負担してもらうことを予定しています。
しかし一つの組織の利益につながるようなシステムは、将来的な持続可能性の点で問題があると考えられます。金銭的な負担が大きければ、デジタルディバイドも問題となるでしょう。そこでモデルの変更や、モデル切り替え機能の実装も私たちは検討しています。
生成AIは学習したデータに基づいて、新たなデータを生成するシステムです。ヒューマニテクストが、西洋古典や人文学を誰にとっても身近にする一方、先人たちの叡智の価値を再確認させてくれるシステムになることを期待しています。
※ヒューマニテクストについてより知りたい方は添付したプレスリリース文、またテレビの取材映像をご覧ください。
- NHK 東海 NEWS WEB「【特集】知の巨人たちに相談! 名大など開発AI対話システム」(2024年6月2日)(https://www3.nhk.or.jp/tokai-news/20240612/3000035974.html)
- NHK「NHKニュースおはよう日本 注目の経済&世界の話題をまとめて!」(6/13(木) 午前6:30-午前7:00)(https://plus.nhk.jp/watch/st/g1_2024061311634?t=511)※視聴期限があります。
- NHK NEWS WEB「偉人たちに相談だ!現代の悩みをどう解決してくれるの?」(2024年6月12日)(https://www3.nhk.or.jp/news/html/20240612/k10014478351000.html)
また、ヒューマニテクストのプロトタイプ版の開発については、以下の論文をご参照ください。
- 岩田直也, 田中一孝, 小川潤(2024)「大規模言語モデルを活用した西洋古典研究と教育」『第38回人工知能学会全国大会論文集』(https://doi.org/10.11517/pjsai.JSAI2024.0_1N4OS1805)
謝辞
日本西洋古典学会第74回大会における本システムの報告のために、ご調整いただいた日本西洋古典学会委員長の高橋宏幸先生、事務局長の河島思朗先生、会場校(神戸大学)の佐藤昇先生には深く感謝を申し上げます。